
Ngày nay, chấn thương khớp gối là một trong những chấn thương phổ biến nhất trong thể thao, tai nạn lao động và tai nạn giao thông [1]. Nếu không được chẩn đoán, xử lý đúng cách, kịp thời, chấn thương khớp gối dễ gây ra hậu quả nghiêm trọng cho bệnh nhân, ảnh hưởng đến chức năng vận động của khớp gối [2]. Do đó, có thể áp dụng việc sử dụng hình ảnh MRI kết hợp với trí tuệ nhân tạo để đưa ra dự đoán chính xác và nhanh chóng về tình trạng chấn thương của bệnh nhân là hết sức cần thiết [3].

Ngoài ra, “Trí tuệ nhân tạo” hay còn được biết đến thông qua hai từ quen thuộc “AI”, là một trong những phân mảng mới nhất thuộc ngành khoa học máy tính, đã và đang thu hút rất nhiều sự chú ý từ các nhà khoa học. Có thể thấy rằng, trong vòng 5 năm trở lại đây, sự phát triển của trí tuệ nhân tạo trên thế giới đã có những bước tiến vượt bậc cũng như tính ứng dụng rộng rãi trong các lĩnh vực có liên quan đến phân tích dữ liệu, đặc biệt là trong chẩn đoán các bệnh lý [3, 4]. Cụ thể hơn, những phát triển gần đây trong trí tuệ nhân tạo đã tạo ra sự thay đổi lớn về khả năng nhận dạng, xác định đặc tính và đo lường các bệnh lý phức tạp trong cơ thể con người thông qua máy tính [5]. Trong nghiên cứu này, chúng tôi sẽ tạo ra một mô hình trí tuệ nhân tạo để áp dụng trong chẩn đoán chấn thương khớp gối dựa trên các đặc điểm của dữ liệu hình ảnh MRI.
Trong những tiến bộ gần đây của khoa học máy tính, trí tuệ nhân tạo (AI) đã trở thành một xu hướng đi đầu nổi bật của các ứng dụng máy tính, từ tìm kiếm trên trang web, lái xe tự động, xử lý ngôn ngữ và các kỹ thuật khác – những nhiệm vụ mà cho đến vài năm trước đây, chúng chỉ có thể được thực hiện bởi con người [6-9]. Tổng quát hơn, định nghĩa về trí tuệ nhân tạo đề cập đến một lĩnh vực trong khoa học máy tính dành riêng cho việc tạo ra các hệ thống thực hiện các nhiệm vụ dựa trên sự mô phỏng trí thông minh của con người, bao gồm nhiều kỹ thuật khác nhau.
Năm 1959, Arthur Samuel giới thiệu “Machine Learning” (học máy – ML) như là một tập hợp con của công nghệ trí tuệ nhân tạo [10] bao gồm tất cả những phương pháp cho phép các máy tính học hỏi từ dữ liệu mà không cần lập trình một cách rõ ràng, đã được áp dụng rộng rãi để phân tích hình các hình ảnh và đưa ra chẩn đoán [11, 12], đặc biệt là với lĩnh vực chẩn đoán hình ảnh [13]. Trong số tất cả các kỹ thuật nằm trong học máy, học sâu (Deep Learning – DL) đã nổi lên như một trong những khía cạnh mới và hứa hẹn nhất.
Thật vậy, dữ liệu là một kỹ thuật thuộc học máy, và đều là phân nhánh công nghệ trong “gia đình” AI rộng lớn. Cụ thể, các phương thức dữ liệu thuộc về các phương pháp học trình diễn với nhiều cấp độ biểu diễn, xử lý dữ liệu thô để thực hiện các nhiệm vụ phân loại hoặc phát hiện. Thành công trong ứng dụng dữ liệu có thể chủ yếu nhờ vào những tiến bộ gần đây trong việc phát triển các công nghệ phần cứng, như các đơn vị xử lý đồ họa [14].
Phương pháp dữ liệu được phát triển để cải thiện hiệu suất của mạng thần kinh mô phỏng nhân tạo (ANN) thông thường khi sử dụng các kiến trúc sâu [15, 16]. Một ANN sâu khác với lớp ẩn đơn ở chỗ chúng có một số lượng lớn các lớp ẩn, đặc trưng cho độ sâu của mạng. Trong số các ANN sâu khác nhau, mạng nơ ron tích chập (CNN) đã trở nên phổ biến trong các ứng dụng thị giác máy tính (phân tích hình ảnh). Trong lớp ANN sâu này, các phép toán tích chập được sử dụng để thu thập các đặc tính đặc trưng của hình ảnh trong đó cường độ của từng pixel/voxel được tính bằng tổng của từng pixel/voxel của ảnh gốc và các lân cận của nó, được tính bằng ma trận kết hợp (còn được gọi là ma trận hạt nhân els) [17]. CNNs bắt chước cảm ứng dựa trên hành vi của vỏ não, một cấu trúc phức tạp của các tế bào nhạy cảm với những vùng nhỏ của vùng thị giác [18]. Kiến trúc của các CNN sâu cho phép cấu thành từ các tính năng phức tạp (như hình dạng) đến các tính năng đơn giản hơn (ví dụ cường độ hình ảnh) để giải mã dữ liệu thô của hình ảnh mà không cần phải phát hiện các tính năng cụ thể [16]. Vì lý do này, các mạng dữ liệu yêu cầu một lượng dữ liệu đào tạo khổng lồ, từ đó tăng sức mạnh tính toán cần thiết để phân tích chúng.
Theo xu hướng, trí tuệ nhân tạo trong các lĩnh vực y khoa, có một lượng lớn dữ liệu hình ảnh được thu thập trong quá trình thực hành lâm sàng thông thường, đặc biệt là tại các bệnh viện của các nước đang phát triển như Việt Nam. Theo Filippo Pesapane và cộng sự [19] bộ dữ liệu lớn về dữ liệu hình ảnh trong y tế như chẩn đoán hình ảnh, các biểu hiện bệnh lý trên lâm sàng, da liễu…đã trở thành nguồn tài nguyên phong phú cho các nhà nghiên cứu.

Ngay từ những năm 1960, các bác sĩ chẩn đoán hình ảnh đã quen với việc sử dụng các hệ thống phát hiện/chẩn đoán (CAD) được hỗ trợ bởi máy tính, lần đầu tiên được áp dụng trong các ứng dụng X quang và chụp nhũ ảnh [20, 21]. Nó cũng có thể cho tỷ lệ dương tính giả cao khi thực hành với dữ liệu hình ảnh có độ nhạy cao như chụp nhũ ảnh, dẫn đến không hiệu quả và các xét nghiệm không cần thiết trong chăm sóc bệnh nhân lâm sàng [22]. Với những tiến bộ trong sự phát triển thuật toán hiện tại, kết hợp với việc dễ dàng truy cập vào tài nguyên dữ liệu y học trực tiếp từ bệnh viện lớn (hơn một nghìn trường hợp được chẩn đoán bằng hình ảnh MRI mỗi ngày/bệnh viện) [23], điều này sẽ cho phép trí tuệ nhân tạo được áp dụng trong việc chẩn đoán hình ảnh với khả năng chính xác cao hơn [23, 24]. Hơn nữa, với các kỹ thuật dựa trên học tập sâu mới, các mô hình trí tuệ nhân tạo có thể làm giảm tỷ lệ dương tính giả và cho phép chẩn đoán chính xác hơn trong các bệnh lý y học [25].
Trong thời gian gần đây, một mô hình trí tuệ nhân tạo mang tên EfficientNet đã cách mạng hóa cách chúng ta tiếp cận khoa học máy tính với dữ liệu đầu vào có kích thước khác nhau với khả năng mở rộng khả năng ứng dụng của chúng [26]. Các mô hình CNN tương tự đã được đề xuất kể từ khi EfficientNet được thiết kế, chủ yếu tập trung vào nhiệm vụ chính là đạt được độ chính xác phân loại tốt hơn và thời gian huấn luyện nhanh hơn với một số lượng nhỏ các tham số [26, 27]. Mô hình này được lập ra cách đây 2 năm, và khá phổ biến vì cách mà mô hình mở rộng quy mô ứng dụng, đồng thời giúp quá trình đào tạo của mô hình nhanh hơn nhiều so với các mô hình khác. Gần đây, Google đã phát hành EfficientNetV2, đây là một cải tiến lớn so với mô hình EfficientNet về tốc độ đào tạo và cải thiện đáng kể về độ chính xác [27].
Đồng thời, việc giảm thông số đầu vào và khả năng mở rộng linh hoạt của cấu trúc EfficientNetV2 đã góp phần vào mở rộng khả năng ứng dụng của chúng trong việc dự đoán các chấn thương gối mà không cần lượng lớn dữ liệu đầu vào (khó thu thập dữ liệu ở các nước đang phát triển và phải được sự đồng ý của hội đồng đạo đức y học) [27, 28]. Đồng thời, điều này cũng giúp mô hình này được áp dụng cho việc nhận diện các hình ảnh có kích thước khác nhau, dễ dàng tích hợp chúng vào nghiên cứu đa trung tâm ngay cả khi có dữ liệu đầu vào có kích thước khác nhau [27].
I.Mục tiêu nghiên cứu
Mục tiêu dài hạn của nghiên cứu là phát triển một mô hình trí tuệ nhân tạo chính thức để hỗ trợ chẩn đoán hình ảnh trong chấn thương khớp gối thông qua việc sử dụng hình ảnh MRI khớp gối. Mô hình này sẽ hỗ trợ các bác sĩ trong quá trình xác định và phân loại các chấn thương, bệnh lý cơ xương khớp nói chung và chấn thương khớp gối nói riêng. Ngoài ra, mục tiêu của nghiên cứu hiện nay là tập trung vào chẩn đoán toàn diện về tổn thương các cấu trúc giải phẫu khớp gối dựa trên công nghệ trí tuệ nhân tạo, đồng thời chứng minh khả năng của trí tuệ nhân tạo trong thực tế và phác thảo khung dự đoán và chẩn đoán làm khái niệm cho các dữ liệu hình ảnh y học khác. Vì vậy, nghiên cứu có các mục tiêu sau:
Để tạo ra một mô hình trí tuệ nhân tạo để chẩn đoán chấn thương khớp gối với độ chính xác cao, nhanh dựa trên hình ảnh MRI khớp gối
Để so sánh độ chính xác hiện tại của chẩn đoán hình ảnh MRI trong thực tiễn và so sánh với chẩn đoán được hỗ trợ bởi mô hình trí tuệ nhân tạo
Kết quả của nghiên cứu này sẽ có giá trị đối với các chẩn đoán trong các ứng dụng y khoa cũng như cung cấp một công cụ hoặc phần mềm trong việc phát triển thực hành chẩn đoán tốt hơn. Ngoài ra, trí tuệ nhân tạo thúc đẩy việc áp dụng các công cụ và các mô hình được xây dựng tương tự trên hình ảnh MRI từ dự án này tại các bệnh viện ở Việt Nam.
II. Đối tượng và phương pháp nghiên cứu
II.1. Đối tượng nghiên cứu
Bộ dữ liệu bao gồm các kết quả hình ảnh học MRI khớp gối từ Bệnh viện Chợ Rẫy được chia thành 2 nhóm: nhóm huấn luyện trí tuệ nhân tạo và nhóm kiểm chứng.
Nhóm huấn luyện trí tuệ nhân tạo:
Tiêu chuẩn chọn bệnh: 1000 bệnh nhân chấn thương khớp gối được chẩn đoán và điều trị tại khoa Chấn thương – Chỉnh hình bệnh viện Chợ Rẫy. Bao gồm 1000 kết quả hình ảnh học MRI khớp gối trong khoản thời gian 3 năm (ngày 1 tháng 1 năm 2019 – ngày 31 tháng 12 năm 2021) được đọc kết quả bởi các bác sĩ chẩn đoán hình ảnh. Các kết quả MRI được chọn đã được đối chiếu với kết quả tổn thương ghi nhận trong mổ của bệnh nhân và đều cho kết quả tương đồng.
Tiêu chuẩn loại trừ: các bệnh nhân chấn thương khớp gối có kết quả MRI được đọc bởi các bác sĩ chẩn đoán hình ảnh có kết quả khác biệt với kết quả tổn thương được ghi nhận trong mổ.
Sau khi có đủ các số liệu, chúng tôi tiến hành huấn luyện trí tuệ nhân tạo với mô hình 2D – CNN: EfficientNetV2 với 5 phiên bản B0, B1, B2, B3 và S.
Nhóm kiểm chứng trí tuệ nhân tạo:
183 bệnh nhân chấn thương khớp gối được chẩn đoán và điều trị tại khoa Chấn thương – Chỉnh hình bệnh viện Hoàn Mỹ Đà Nẵng (từ ngày 1 tháng 1 năm 2020 – ngày 31 tháng 05 năm 2020), được thu thập thông tin đầy đủ từ bệnh án: thông tin hành chính, chẩn đoán ra viện, kết quả MRI, và tường trình phẫu thuật. Cụ thể:
Kết quả tổn thương gối của bệnh nhân được ghi nhận trong mổ.
Nhóm 1: Kết quả 183 hình ảnh học MRI khớp gối được đọc kết quả bởi mô hình trí tuệ nhân tạo.
Nhóm 2: Kết quả 183 hình ảnh học MRI khớp gối được đọc kết quả bởi nhóm 1 các bác sĩ chẩn đoán hình ảnh.
Sau khi thu thập kết quả từ 3 nguồn trên, chúng tôi sẽ so sánh các kết quả của 2 nhóm và dùng kết quả tổn thương gối của bệnh nhân trong mổ làm đối chiếu để đánh giá sự khác biệt giữa việc có và không có hỗ trợ của trí tuệ nhân tạo trong chẩn đoán hình ảnh.
II.2. Phương pháp nghiên cứu
II.2.1. Phân loại và sắp xếp dữ liệu
Sau khi mô hình trí tuệ nhân tạo được thiết lập dựa trên dữ liệu của nhóm huấn luyện với 1000 kết quả hình ảnh học MRI khớp gối, dữ liệu MRI của nhóm kiểm chứng sẽ được sử dụng để xác minh tính chính xác của nghiên cứu thông qua so sánh giữa kết quả dự đoán và chẩn đoán của nhóm 1 có hỗ trợ của mô hình trí tuệ nhân tạo so với nhóm 2 không có hỗ trợ của trí tuệ nhân tạo và kết quả tổn thương gối của bệnh nhân được ghi nhận trong mổ.
Kết quả hình ảnh học MRI với một hoặc nhiều chẩn đoán sau đây được coi là phù hợp cho mục đích của dự án này: rách dây chằng chéo trước, rách dây chằng chéo sau, rách sụn chêm, chấn thương dây chằng bên trong, chấn thương dây chằng bên ngoài, hoặc đa chấn thương phối hợp nhiều tồn thương cấu trúc giải phẫu khớp gối, v.v… Ngoài ra, chúng tôi sẽ bổ sung danh mục các loại tổn thương không thường gặp khác và đưa vào cho mô hình trí tuệ nhân tạo phát hiện và phân loại như dập xương dưới sụn, gãy xương, thoái hóa khớp gối…
II.2.2. Mô hình trí tuệ nhân tạo EfficientNetV2
Đối với tất cả các dữ liệu MRI gối, chúng tôi lấy các lát cắt ở trung tâm và định hình lại nó thành kích thước huấn luyện mặc định của các mô hình định sẵn. Tất cả được tối ưu hóa bằng cách sử dụng trình tối ưu hóa NAdam (Adam với động lượng Nesterov) với tỷ lệ học giống nhau trên tất cả các hợp đào tạo. Chúng tôi huấn luyện tất cả các mô hình trong 100 vòng lặp với kích thước phân vùng là 32. Mỗi mô hình chúng tôi đã áp dụng đồng thời mức giảm trọng lượng L2 là 0,01 và tỷ lệ bỏ huấn luyện là 0,2 để ngăn ngừa tình trạng tương thích quá mức của mô hình.
II.2.3. Tính năng khai thác
Để huấn luyện hệ thống trí tuệ nhân tạo, chúng tôi sẽ chuẩn bị các cấu trúc được phân loại cụ thể và các đặc điểm hình ảnh được trích xuất có thể dễ dàng nhìn thấy hoặc khó phát hiện đối với mắt thường. Cách tiếp cận này bắt chước nhận thức phân tích của con người, cho phép đạt được hiệu suất tốt hơn so với các phần mềm CAD cũ khác. Theo các nghiên cứu trước đây của chúng tôi, các nhà nghiên cứu đã chia bộ tính năng thành nhiều loại, tuy nhiên, trong dự án này, chúng tôi sẽ tập trung vào 2 tính năng chính của hình ảnh MRI là: hình thái giải phẫu và chức năng.
Các đặc điểm hình thái trong dự án này sẽ tập trung vào cả hai tham số hai chiều (2D) và ba chiều (3D). Các đặc điểm hình thái 2 chiều bao gồm đường kính trung bình, chiều dài tiêu chuẩn, diện tích vùng tổn thương tối đa và tối thiểu; chu vi; phức tạp; chiều dài xuyên tâm… Đặc biệt, những hình ảnh MRI này không chỉ thu được bởi một hình ảnh, mà chúng còn được dẫn xuất nhiều lát cắt. Do đó, các tính năng 3 chiều trong dự án này sẽ được chỉ định rõ hơn để phác thảo chính xác nhất các vùng tổn thương thường bao gồm các khía cạnh khác nhau như: đường tròn , độ nén, độ mịn, độ nhám, độ xốp, độ lệch tâm, khối lượng, hình chữ nhật, độ rắn, độ lồi, độ cong, và các cạnh của các thành phần cấu trúc trong khớp gối.
Bên cạnh các đặc điểm hình thái nhằm mục đích xác định các tổn thương được đánh giá tốt trong MRI khớp gối, chúng tôi còn căn cứ vào nhiều loại chỉ số chức năng khác nhau bao gồm: diện tích, tỷ lệ cường độ tối đa, cường độ tương đối, độ dốc tăng cường tương đối, tín hiệu cơ bản, chỉ số tưới máu, SOD, rửa và thời gian đạt cực đại… Để tăng cường độ chính xác của mô hình trí tuệ nhân tạo, số lượng các chỉ số chức năng và hình thái giải phẫu được chọn bằng quy trình chọn chi tiết và loại bỏ các tính năng không quan trọng để giảm độ nhiễu.
II.2.4. Phân lớp và phương pháp học sâu
Trong nghiên cứu này, chúng tôi sẽ phân loại hình ảnh dựa trên 2 lớp:
Lớp chính: Trong bước này, chúng tôi sẽ phân loại hình ảnh MRI của 1000 trường hợp thành 2 lớp phụ là bình thường và bất thường. Lớp bình thường được trình bày cho các trường hợp bình thường mà không có bất kỳ thương tích nào, trong khi đó lớp bất thường có mặt trong tổng số các trường hợp chấn thương.
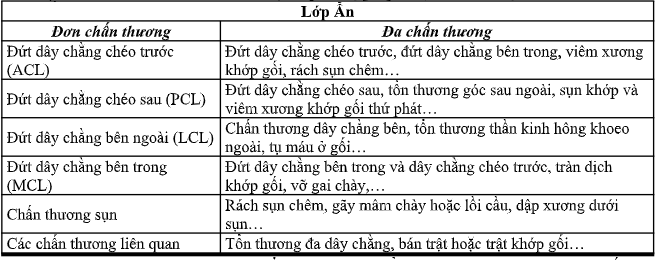
Lớp ẩn: Lớp này là quan trọng nhất trong dự án này. Các phụ lớp trong lớp ẩn này đại diện cho từng trường hợp cụ thể chấn thương khớp gối. Tất cả các chấn thương đơn thuần và chấn thương phối hợp của khớp gối được liệt kê dưới dạng các lớp con trong lớp ẩn này (Bảng 1). Các chi tiết này được ghi nhận và phân loại ở lớp con trong lớp ẩn và phân tích cẩn thận các tính năng, do đó, việc chẩn đoán hình ảnh thương tích trên mô hình này của chúng ta sẽ nhận được hiệu quả cao.
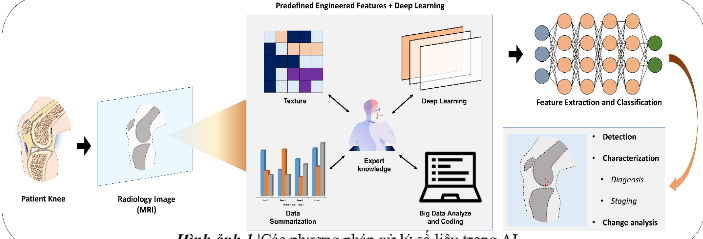
Những tiến bộ gần đây trong nghiên cứu trí tuệ nhân tạo đã tạo ra các thuật toán học sâu mới cung cấp khả năng giải quyết vấn đề vượt trội trong các lĩnh vực khác nhau với hiệu suất cao, đại diện cho một mô hình khác biệt cơ bản trong học máy trước đây. Nó cũng có thể được áp dụng trong chẩn đoán hình ảnh y học và đem lại hiệu suất cao. Các phương pháp phân tích lớp ẩn của học sâu đã tồn tại trong nhiều thập kỷ. Tuy nhiên, chỉ trong những năm gần đây, điều này mới phát huy ưu điểm do có đủ dữ liệu và sức mạnh của các thuật toán. Dựa trên sự phát triển mạnh mẽ của các thuật toán học sâu, có nhiều công cụ để sử dụng trong nghiên cứu trí tuệ nhân tạo như mạng lưới thần kinh mô phỏng sâu, bộ mã hóa tự động xếp chồng, máy Boltzmann sâu và mạng lưới thần kinh mô phỏng tích chập (CNN).
Trong đề tài này, chúng tôi sẽ tập trung vào các mạng lưới thần kinh mô phỏng tích chập 2D (2D-CNN) vì đây là những kiểu kiến trúc học sâu phổ biến nhất trong phân tích hình ảnh nói chung và hình ảnh y học hiện nay. Một CNN điển hình bao gồm một loạt các lớp liên tục ánh xạ các đầu vào hình ảnh đến các điểm cuối mong muốn với khả năng học tập các tính năng hình ảnh ngày càng cao hơn. Bắt đầu từ một hình ảnh đầu vào, ‘các lớp ẩn’ trong CNN thường bao gồm một loạt các hoạt động tích chập và gộp chung trích xuất bản đồ tính năng và thực hiện tổng hợp tính năng tương ứng. Trong dự án này, các lớp ẩn này được trình bày trong Bảng 1, sau đó tiếp theo là các lớp được kết nối đầy đủ cung cấp lý luận cấp cao trước khi một lớp đầu ra được tạo ra từ các dự đoán.
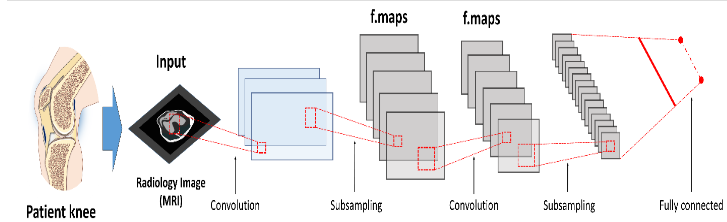
II.2.5. Huấn luyện mô hình trí tuệ nhân tạo:
Mỗi kết quả MRI có 3 loại mặt phẳng: đứng bên, trước sau và mặt phẳng ngang. Đối với mỗi tổn thương, chúng tôi đã huấn luyện một quá trình phân loại hồi quy tuyến tính để kết hợp cả 3 kết quả hình ảnh trên 3 mặt phẳng của mô hình nhằm tạo ra một xác suất dự đoán duy nhất cho phép thử. Theo đó, các kết quả MRI được dán nhãn dữ liệu (label data) theo từng loại tổn thương đã được lập danh sách, sau đó các tổn thương sẽ được phân khúc cụ thể (segmentation) theo từng mặt phẳng riêng. Khi các bước dán nhãn dữ liệu được hoàn tất, chúng tôi tiến hành chạy mô hình với cấu trúc dữ liệu đa dán nhãn (multi-label).
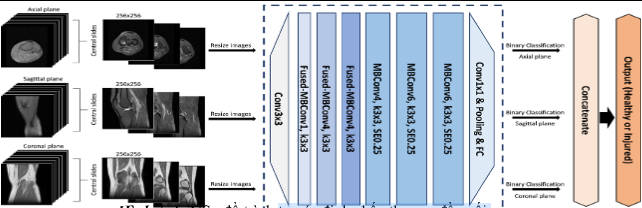
II.2.6. Phương pháp thống kê
Chúng tôi đã đánh giá hiệu suất mô hình với các khu vực dưới đường cong đặc tính vận hành máy thu (AUC). Để đánh giá sự thay đổi trong ước tính, chúng tôi cung cấp khoảng tin cậy điểm Wilson 95% về độ nhạy, độ đặc hiệu và độ chính xác và khoảng tin cậy DeLong 95% cho AUC. Ngưỡng tin cậy 0,05 đã được sử dụng để phân đôi các dự đoán mô hình. Hiệu suất mô hình trên bộ xác nhận bên ngoài được đánh giá với khoảng tin cậy AUC và 95% DeLong.
Ở phần kiểm chứng, chúng tôi đã đánh giá lợi ích lâm sàng của mô hình trí tuệ nhân tạo này bằng cách so sánh xem tỷ lệ chính xác so với kết quả phẫu thuật trên nhóm 1 có tăng lên so với nhóm 2 khi họ được hỗ trợ mô hình hay không. Tất cả các phân tích thống kê đã được hoàn thành bằng phần mềm R để tính toán thống kê.
III. Kết quả
III.1. Hiệu quả của mô hình trí tuệ nhân tạo
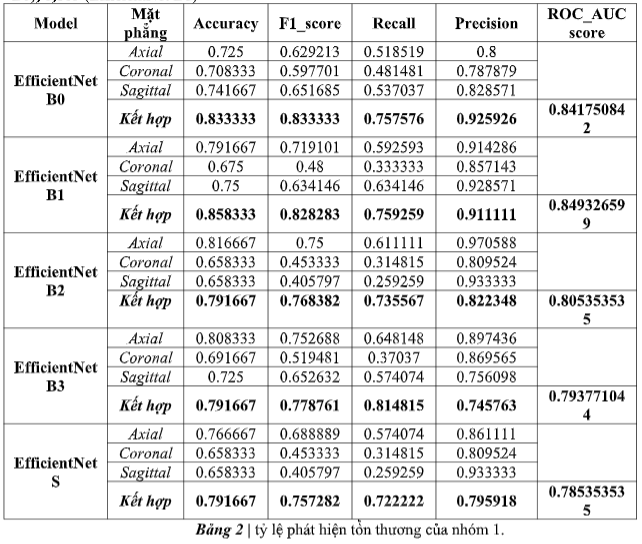
Để phát hiện các tổn thương, mô mình trí tuệ nhân tạo hỗ trợ nhóm 1 phát hiện các tổn thương kèm, rách dây chằng chéo trước và phát hiện rách sụn chêm đã đạt được AUC lần lượt là 0,842 (EfficientNet B0), 0,805 (EfficientNet B1)
III.2. Hiệu quả của mô hình trí tuệ nhân tạo so với nhóm 2
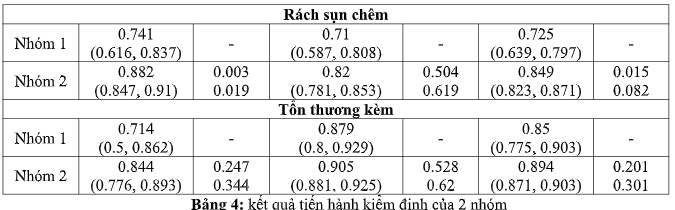
Trong vai trò phát hiện những tổn thương khác, không có sự khác biệt đáng kể về số liệu hiệu suất nhóm 1 có sự hổ trợ của mô hình trí tuệ nhân tạo và nhóm 2 (Bảng 4). Độ đặc hiệu mô hình để phát hiện tổn thương khác của nhóm 1 thấp hơn của nhóm 2, lần lượt là 0,714 (95% CI 0,500, 0,862) và 0,844 (95% CI 0,776, 0,893). Mô hình trí tuệ nhân tạo đạt được độ nhạy 0.879 (95% CI 0.800, 0.929) và độ chính xác là 0.850 (95% CI 0.775, 0,903), trong khi nhóm 2 nói chung đạt được độ nhạy 0,905 (95% CI 0,881, 0,924) và độ chính xác là 0,894 ( KTC 95% 0.871, 0.913) (Bảng 4).
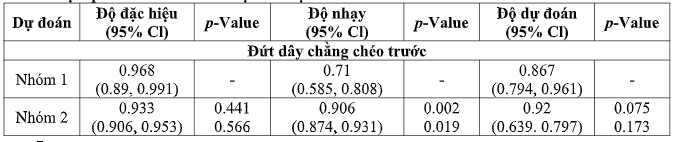
Nhóm 1 có sự hổ trợ của mô hình trí tuệ nhân tạo này có độ đặc hiệu cao để phát hiện rách dây chằng chéo trước, đạt độ đặc hiệu 0,968 (95% CI 0,890, 0,991), cao hơn mức trung bình kết quả đọc của nhóm 2 nói chung, ở mức 0,933 (95% CI 0,90, 0,953), nhưng sự khác biệt này không có ý nghĩa thống kê (Bảng 4).
Kết quả đọc của nhóm 2 đạt được độ nhạy cao hơn đáng kể so với nhóm 1 có sự hổ trợ của mô hình trí tuệ nhân tạo trong phát hiện rách dây chằng chéo trước (q-value = 0,002, q-value = 0,009); độ nhạy của nhóm 2 nói chung trung bình là 0,90 (95% CI 0,874, 0,931), trong khi nhóm 1 có sự hổ trợ của mô hình trí tuệ nhân tạo đạt được độ nhạy 0,759 (95% CI 0,635, 0,850) (Bảng 2).
Kết quả thu lại từ nhóm 2 cũng đạt được độ đặc hiệu cao hơn đáng kể trong việc phát hiện rách sụn chêm (p-value = 0,003, q-value = 0,009), với độ đặc hiệu là 0,892 (95% CI 0,858, 0,918) tương ứng với độ đặc hiệu là 0,741 (95% CI 0,616, 0,837) so với nhóm 1 có sự hổ trợ của mô hình trí tuệ nhân tạo. Không có sự khác biệt đáng kể nào trong các số liệu hiệu suất (Bảng 4).
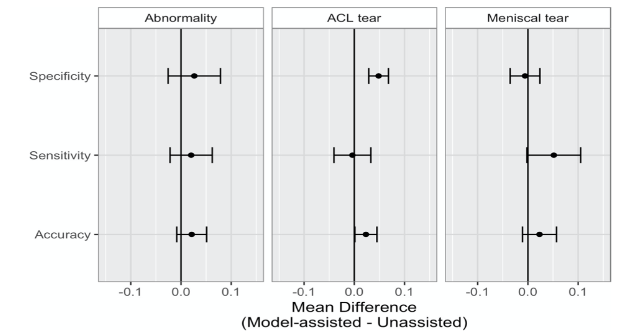
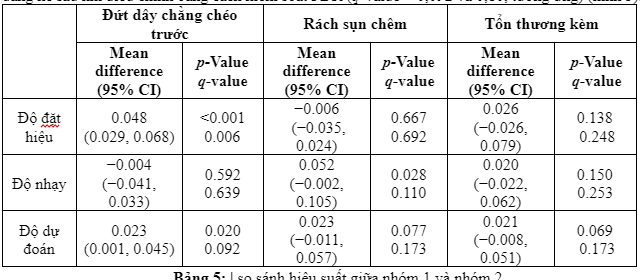
Khi nhóm 1 có hỗ trợ mô hình trí tuệ nhân tạo, có sự gia tăng đáng kể về mặt thống kê về tính đặc hiệu của các chuyên gia lâm sàng trong xác định đứt dây chằng chéo trước (p-value <0,001, nhóm q-value = 0,006). Mức tăng trung bình của độ đặc hiệu đứt dây chằng chéo trước là 0,048 (4,8%) (bảng 5), sự gia tăng độ đặc hiệu này có thể đưa ra giả định là có khoản 8 bệnh nhân được gửi đến phẫu thuật vì nghi ngờ đứt dây chằng chéo trước không cần thiết. Mặc dù có vẻ như sự trợ giúp mô hình trí tuệ nhân cũng làm tăng đáng kể độ chính xác của nhóm 1 trong việc phát hiện đứt dây chằng chéo trước (q-value = 0,020) và độ nhạy trong việc phát hiện rách sụn chêm (q-value = 0,028), những phát hiện này không còn đáng kể sau khi điều chỉnh bằng cách kiểm soát FDR (q-value = 0,092 và 0,10, tương ứng) (hình 5).
IV. Bàn luận
Mục đích của nghiên cứu này là phát triển và đánh giá một mô hình trí tuệ nhân tạo để chẩn đoán chấn thương khớp gối trên MRI và sau đó so sánh hiệu suất với các bác sĩ chẩn đoán hình ảnh. Kết quả của chúng tôi chứng minh rằng nhóm có sự hổ trợ của mô hình trí tuệ nhân tạo có thể đạt được hiệu suất cao trong chẩn đoán chấn thương khớp gối trên MRI, với AUC để phát hiện tổn thương kèm, phát hiện đứt dây chằng chéo trước và phát hiện rách sụn chêm lần lượt là 0,842 (EfficientNet B0), 0,849 (EfficientNet B1). Đáng chú ý, nhóm có sự hổ trợ của mô hình trí tuệ nhân tạo đạt được độ đặc hiệu cao trong việc phát hiện đứt dây chằng chéo trước, điều này cho thấy rằng với một mô hình trí tuệ nhân tạo như vậy, nếu được sử dụng trong quy trình lâm sàng, có thể có khả năng giảm sai sót một cách hiệu quả.
Sự phát triển của các mô hình học sâu cũng đi kèm với việc áp dụng chúng trong các lĩnh vực cụ thể, đặc biệt là trong các lĩnh vực Y học. Có thể thấy, trong 5 năm trở lại đây, số lượng các nghiên cứu về mô hình học sâu trên hình ảnh y học đã tăng lên đáng kể, đặc biệt là trong chẩn đoán chấn thương hoặc ung thư [24]. Đứt dây chằng chéo trước là một trong những chấn thương phổ biến nhất ở khớp gối, và việc áp dụng mô hình học sâu trong việc tự động nhận biết chấn thương là rất cần thiết [29]. Một số nghiên cứu đã chứng minh rằng việc sử dụng các công cụ nhận dạng dựa trên học sâu có thể giúp cải thiện độ chính xác, độ nhạy và thời gian chẩn đoán cho bác sĩ chẩn đoán hình ảnh (một số tổn thương nhỏ và cụ thể trên hình ảnh khó phát hiện bằng mắt thường) [29]. Bien và cộng sự [30] đã sử dụng hình ảnh MRI của 1370 bệnh nhân để hướng dẫn và thực hiện một phương pháp học sâu để phát hiện đứt dây chẳng chéo trước dựa trên kết quả đọc của các bác sĩ chẩn đoán hình ảnh có kinh nghiệm làm tiêu chuẩn tham chiếu. Mô hình học sâu của họ có độ nhạy và độ đặc hiệu lần lượt là 0,76 và 0,97 để phát hiện thành công 319 ca đứt dây chẳng chéo trước, với độ nhạy của mô hình thấp hơn đáng kể (P = 0,002) so với các bác sĩ X quang lâm sàng. Mặt khác, Peter D. Chang và cộng sự [29] cũng đã công bố một nghiên cứu với mô hình học sâu kiểm tra đứt dây chẳng chéo trước (0,971, 0,967, 1,00 AUC, độ nhạy, độ đặc hiệu, tương ứng) dựa trên tính khả thi và lợi ích của một số kiến trúc mạng tùy chỉnh trên tổng số 260 bệnh nhân ở độ tuổi 18– 40 trong một nghiên cứu hồi cứu.
Mặc dù đã có những nghiên cứu so sánh hoạt động của các mô hình CNN với nhau hoặc với các bác sĩ chẩn đoán hình ảnh để chỉ ra độ chính xác của mô hình, nhưng hầu hết các mô hình này vẫn chưa được áp dụng vào thực tế do cần một lượng lớn chi phí và dữ liệu để triển khai (như AlexNet hoặc ResNet) [31]. Ví dụ, nghiên cứu của Fang Liu và cộng sự đã tiến hành một cuộc khảo sát về ba mô hình phân loại khác nhau dựa trên CNN, bao gồm DenseNet, VGG16 và AlexNet [32]. Trong đó, DenseNet được coi là thuật toán cung cấp hiệu suất chẩn đoán tốt nhất trong việc phát hiện các trường hợp đứt dây chẳng chéo trước. So với các thuật toán CNN khác, AlexNet có kiến trúc mạng nơ-ron rất đơn giản, đây có thể là lý do tại sao mô hình AlexNet có hiệu quả chẩn đoán thấp [33].
Trên thực tế, VGG16 là một thuật toán có kiến trúc phức tạp, tuy nhiên, thuật toán này yêu cầu một lượng lớn dữ liệu đầu vào để đạt được hiệu suất tối ưu [34, 35]. Sự ra đời của EfficientNetV2 đã giải quyết một phần vấn đề này thông qua việc mô hình này có khả năng cung cấp độ chính xác cao, tốc độ huấn luyện nhanh và các thông số cần thiết cho một mô hình khá thấp so với các mô hình khác. hình ảnh CNN trước đó (Bảng 2). Trong nghiên cứu này, chúng tôi đã xây dựng một mô hình học sâu để dự đoán đứt dây chẳng chéo trước với mô hình cốt lõi là EfficientNetV2.
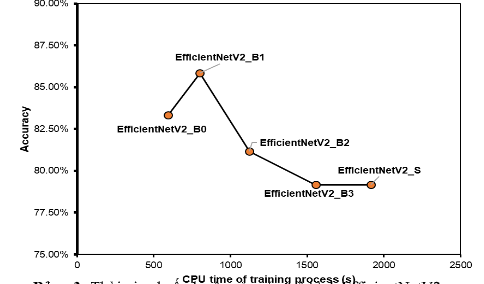
Chúng tôi nhận thấy rằng các mô hình EfficienttNetV2 phiên bản B0 hoặc B1 hoàn toàn phù hợp với một tập dữ liệu nhỏ để tránh tình trạng lãng phí quá nhiều tài nguyên dữ liệu cho việc huấn luyện. Toàn bộ quá trình huấn luyện mô hình của chúng tôi được thực hiện trên Google Colab GPU với thời gian đào tạo trung bình cho hơn 1000 mẫu bệnh nhân trên 1 mặt phẳng là dưới 20 phút (Bảng 3) và tốc độ dự đoán trên bộ thử nghiệm là dưới 1 phút. Ngoài ra, để có một mô hình học sâu có độ chính xác cao, người ta thường phải tạo một mô hình được đào tạo trước dựa trên một lượng dữ liệu thống nhất nhất định, mô hình EfficientNetV2 của chúng tôi chúng vẫn cho thấy khả năng dự đoán cao hiệu suất (độ chính xác trên 84%) trên dữ liệu MRI của bệnh nhân. Điều này làm giảm đáng kể các nguồn lực và thời gian dành cho việc tạo các mô hình huấn luyện.
Trong kết quả so sánh của 2 nhóm nghiên cứu (bảng 4), chúng tôi nhận thấy độ đặc hiệu mô hình để phát hiện tổn thương dây chằng chéo trước của nhóm 1 cao hơn của nhóm 2, tuy nhiên độ nhạy và độ dự đoán lại thấp hơn. Ở những kết quả còn lại về phát hiện các tổn thương khác của khớp gối như rách sụn chêm hay tổn thương kèm thì nhóm 2 có phần ưu thế hơn cả về độ nhạy lẫn độ đặt hiệu. Rõ ràng, vai trò của con người trong chẩn đoán hình ảnh học y khoa tới thời điểm này vẫn giữ nguyên giá trị và máy móc vẫn không thể thay thế được con người trong lĩnh vực này.
Tuy nhiên, mô hình trí tuệ nhân tạo sẽ được xem là một công cụ hổ trợ đắc lực cho các bác sĩ chẩn đoán hình ảnh với ưu thế về thời gian đọc của mô hình và số lượng MRI đọc mỗi ngày [4, 19, 36]. Nếu mô hình trí tuệ nhân tạo này tiếp tục phát triển thêm để tăng tính hiệu quả thì nó sẽ giúp giảm bớt áp lực trong công việc, giảm sự mệt mỏi và đồng thời mô hình này sẽ là một công cụ gợi ý khá quan trọng cho bác sĩ chẩn đoán hình ảnh, bác sĩ lâm sàng khi đưa ra chẩn đoán hay phương án điều trị cho bệnh nhân tại những trung tâm y khoa lớn hay bệnh viện tuyến cuối trong hệ thống y tế quốc gia như bệnh viện Chợ Rẫy.
Sự hỗ trợ của mô trí tuệ nhân tạo của chúng tôi đã đạt được một số kết quả ban đầu rất khả quan. Tuy nhiên, vẫn cần phải xem liệu mô hình trí tuệ nhân tạo có thể cho kết quả tốt hơn nếu được huấn luyện với bộ dữ liệu lớn hơn. Chúng tôi cũng nhận thấy rằng việc cung cấp các mô hình trí tuệ nhân tạo cho các chuyên gia lâm sàng và chẩn đoán hình ảnh như là một sự trợ giúp dẫn đến độ đặc hiệu cao hơn đáng kể trong việc xác định đứt dây chằng chéo trước.
Hơn nữa, để giảm áp lực trong công việc của các bác sĩ chẩn đoán hình ảnh, những người cần trung bình hơn 3 giờ để xem xét khoản 120 phim MRI [30], trong khi mô hình trí tuệ nhân tạo cung cấp tất cả các chẩn đoán trong khoản 2 phút [30], cho thấy đây là một công cụ hỗ trợ rất tốt cho các bác sĩ chẩn đoán hình ảnh. Kết quả của chúng tôi cũng cho thấy rằng trí tuệ nhân tạo có thể được áp dụng thành công cho việc chẩn đoán dựa trên kết quả chụp MRI của nhiều cơ quan khác một cách nhanh chóng, giảm thiểu các bỏ sót trong chẩn đoán mà mắt thường khó phát hiện.
Trong nghiên cứu này, chúng tôi cũng có những hạn chế nhất định và cần cải thiện trong thời gian tới. Chúng tôi thực hiện mô hình dự đoán dựa trên trục 2D CNN trên hình ảnh MRI của từng bệnh nhân và riêng từng mặt phẳng, sau đó đưa ra kết quả dự đoán cuối cùng bằng cách tổng hợp kết quả dự đoán trong cả ba mặt phẳng. Mặc dù tốc độ đào tạo và kết quả chẩn đoán cho thấy hiệu quả đáng tin cậy (độ chính xác trên 84%), chúng tôi vẫn thấy rằng việc xây dựng mô hình chỉ trên từng hình ảnh riêng lẻ không mô tả toàn diện các chấn thương và thiếu độ sâu (trong khi hình ảnh MRI có thể dựng thành hình ảnh 3 chiều). Ngoài ra, mô hình dự báo này mới chỉ được thực hiện huấn luyện trên một nguồn dữ liệu của bệnh viện Chợ Rẫy và cần được áp dụng với dữ liệu từ nhiều trung tâm để đảm bảo tính chính xác và linh hoạt của mô hình.

V. Kết luận
Tóm lại, nghiên cứu của chúng tôi đã chứng minh khả năng sử dụng mô hình EfficientNetV2 trong việc dự đoán đứt dây chằng chéo trước thông qua hình ảnh MRI. Hiệu suất dự đoán của mô hình được tổng hợp từ kết quả dự đoán trên cả 3 mặt phẳng trục, mặt phẳng đứng dọc và mặt phẳng ngang với độ chính xác trên 84%. Khảo sát của chúng tôi cũng chứng minh sự phù hợp của mô hình EfficientNetV2 B0 và B1 với dữ liệu nhỏ, số lượng thông số cần thiết và thời gian đào tạo cũng được giảm đáng kể trong nghiên cứu này. Ngoài ra, chúng tôi đã đã chứng minh lợi ích của mô hình EfficientNetV2, là một công cụ hỗ trợ cho các bác sĩ lâm sàng trong quá trình chẩn đoán hình ảnh chấn thương gối dựa vào hình ảnh MRI.
Tiến sĩ, Bác sĩ Trương Nguyễn Khánh Hưng, Khoa Chấn thương – Chỉnh hình, bệnh viện Chợ Rẫy
Dựa trên tài liệu:
1.Nicolini, A.P., et al., Common injuries in athletes’ knee: experience of a specialized center. Acta Ortop Bras, 2014. 22(3): p. 127-31.
2.Gupte, C. and J.P. St Mart, The acute swollen knee: diagnosis and management. J R Soc Med, 2013. 106(7): p. 259-68.
3.Ahuja, A.S., The impact of artificial intelligence in medicine on the future role of the physician. PeerJ, 2019. 7: p. e7702.
4.Hosny, A., et al., Artificial intelligence in radiology. Nat Rev Cancer, 2018. 18(8): p. 500-510.
5.Bohr, A. and K. Memarzadeh, The rise of artificial intelligence in healthcare applications. Artificial Intelligence in Healthcare, 2020: p. 25-60.
6.Azar, A.T. and S. Vaidyanathan, Computational intelligence applications in modeling and control. 2015: Springer.
7.Cockburn, I.M., R. Henderson, and S. Stern, The impact of artificial intelligence on innovation. 2018, National Bureau of Economic Research.
8.Li, B.-h., et al., Applications of artificial intelligence in intelligent manufacturing: a review. 2017. 18(1): p. 86-96.
9.Pannu, A.J.A.I., Artificial intelligence and its application in different areas. 2015. 4(10): p. 79-84.
10.Samuel, A.L., Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development, 1959. 3(3): p. 210-229.
11.Ayat, N.-E., et al. KMOD-A new support vector machine kernel with moderate decreasing for pattern recognition. Application to digit image recognition. in Proceedings of Sixth International Conference on Document Analysis and Recognition. 2001. IEEE.
12.Koch, G., R. Zemel, and R. Salakhutdinov. Siamese neural networks for one-shot image recognition. in ICML deep learning workshop. 2015.
13.Lee, J.G., et al., Deep Learning in Medical Imaging: General Overview. Korean J Radiol, 2017. 18(4): p. 570-584.
14.Holtsnider, B. and B.D. Jaffe, IT manager’s handbook: Getting your new job done. 2012: Elsevier.
15.Abiodun, O.I., et al., State-of-the-art in artificial neural network applications: A survey. Heliyon, 2018. 4(11): p. e00938.
16.Alzubaidi, L., et al., Review of deep learning: concepts, CNN architectures, challenges, applications, future directions. Journal of Big Data, 2021. 8(1): p. 53.
17.Chen, Y., et al., Voxel Deconvolutional Networks for 3D Brain Image Labeling. KDD : proceedings. International Conference on Knowledge Discovery & Data Mining, 2018. 2018: p. 1226-1234.
18.Xu, Y. and M. Vaziri-Pashkam, Convolutional neural networks do not develop brain-like transformation tolerant visual representations. bioRxiv, 2021: p. 2020.08.11.246934.
19.Pesapane, F., M. Codari, and F. Sardanelli, Artificial intelligence in medical imaging: threat or opportunity? Radiologists again at the forefront of innovation in medicine. European radiology experimental, 2018. 2(1): p. 35-35.
20.Khorasani, R., B.J. Erickson, and J. Patriarche, New opportunities in computer-aided diagnosis: change detection and characterization. J Am Coll Radiol, 2006. 3(6): p. 468-9.
21.Patriarche, J.W. and B.J. Erickson, Change detection & characterization: a new tool for imaging informatics and cancer research. Cancer Inform, 2007. 4: p. 1-11.
22.Wood, C., Computer Aided Detection (CAD) for breast MRI. Technol Cancer Res Treat, 2005. 4(1): p. 49-53.
23.Mun, S.K., et al., Artificial Intelligence for the Future Radiology Diagnostic Service. Frontiers in Molecular Biosciences, 2021. 7(512).
24.Lee, L.I.T., et al., The Current State of Artificial Intelligence in Medical Imaging and Nuclear Medicine. BJR Open, 2019. 1(1): p. 20190037.
25.Shen, Y., et al., Artificial intelligence system reduces false-positive findings in the interpretation of breast ultrasound exams. Nature Communications, 2021. 12(1): p. 5645.
26.Tan, M. and Q. Le. Efficientnet: Rethinking model scaling for convolutional neural networks. in International Conference on Machine Learning. 2019. PMLR.
27.Tan, M. and Q.V. Le, Efficientnetv2: Smaller models and faster training. arXiv preprint arXiv:2104.00298, 2021.
28.Ainembabazi, P., et al., A situation analysis of competences of research ethics committee members regarding review of research protocols with complex and emerging study designs in Uganda. BMC Medical Ethics, 2021. 22(1): p. 132.
29.Chang, P.D., T.T. Wong, and M.J. Rasiej, Deep Learning for Detection of Complete Anterior Cruciate Ligament Tear. J Digit Imaging, 2019. 32(6): p. 980-986.
30.Bien, N., et al., Deep-learning-assisted diagnosis for knee magnetic resonance imaging: Development and retrospective validation of MRNet. PLoS Med, 2018. 15(11): p. e1002699.
31.Helwan, A., et al., Radiologists versus Deep Convolutional Neural Networks: A Comparative Study for Diagnosing COVID-19. Computational and Mathematical Methods in Medicine, 2021. 2021: p. 5527271.
32.Hung, T., et al., Prediction of anterior cruciate ligament injury from MRI using deep learning. 2021. 36.
33.Yamashita, R., et al., Convolutional neural networks: an overview and application in radiology. Insights into Imaging, 2018. 9(4): p. 611-629.
34.Yang, H., et al., A novel method for peanut variety identification and classification by Improved VGG16. Scientific Reports, 2021. 11(1): p. 15756.
35.Ganakwar, P. and S. Date, Convolutional Neural Network-VGG16 for Road Extraction from Remotely Sensed Images. Vol. 8. 2020.
36.Neri, E., et al., What the radiologist should know about artificial intelligence – an ESR white paper. Insights into Imaging, 2019. 10(1): p. 44.